Content Center



Featured in Managing Work





Managing Work












Featured Solution
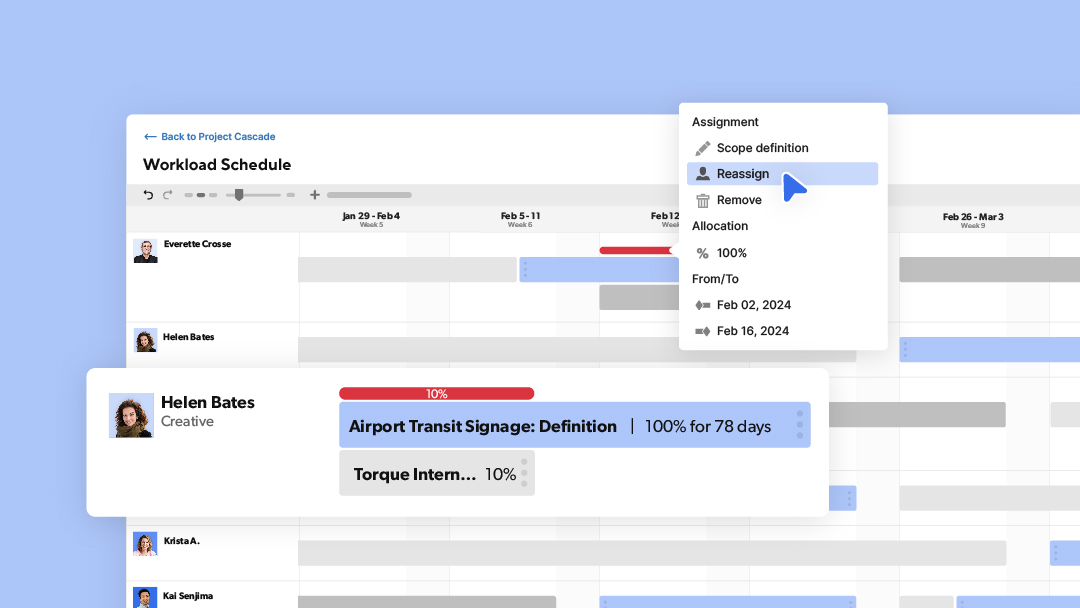
Modern Project and Portfolio Management
From managing one project to an entire portfolio, Smartsheet helps connect the dots between strategy and execution. Learn how you can better manage all the pieces of your program, from strategic alignment and resource allocation through to project delivery and business outcomes.



