How Does a Database Work?
A database starts with volumes of information, known as data. Each piece of data is entered into a field (for example, the title of a song on your favorite album and its composer). Fields are combined to become records (all the songs on the album, and everyone who wrote them). Similar records are combined into a file (your vinyl collection). If you also have a CD collection and a cassette tape collection, the data from those are files too. Together, all those files are a database.
But there’s no connection between the files, so you can’t see if you have Devo’s Duty Now for the Future on both vinyl and CD, or how many cover versions of The Beatles’ “Eleanor Rigby” are in your collection unless you open and search each file. This is called a flat-file database. Flat-file databases can be useful if you don’t have much data to manage, but if you want to compare the contents of each file, you’ll need a relational database.
A relational database differs from a flat-file database because it allows you to make connections between fields and records. Instead of files, relational databases have tables, a set of related data that is displayed in rows and columns to resemble a spreadsheet. Each row in a table is a record.
Examples of database programs include Microsoft Access, MySQL, IBM DB2, SAP Sybase (now known as SAP Adaptive Server Enterprise), and Oracle. Because databases are software, they can be stored on a computer’s hard drive, on a server, or in the cloud.
What Is a Database Table Relationship?
Primary and Foreign Keys
Each record in a table has a unique identifier. It can be a single column (like a student ID number) or a combination of columns (e.g., date and time of file creation plus the customer’s last name). That identifier is called a key.
When a table references the data from another table, it’s called a relationship. The key in the referenced table is called the foreign key, and the key in the referencing table is called the primary key. But it’s a matter of perspective: If table A is linked to table B, determining which is the primary and foreign key depends on which table you are looking at. While a primary key is not required, it is the standard. The primary key and the foreign key must have the same data type (e.g., numeric or alphanumeric) to be related.
Using Relationships
Relationships are the cornerstone of relational databases. Users can query the database and get results that combine data from different tables into a single table. For example, if you own a record store, the database might have a table for albums, another for song titles, and another for artists.
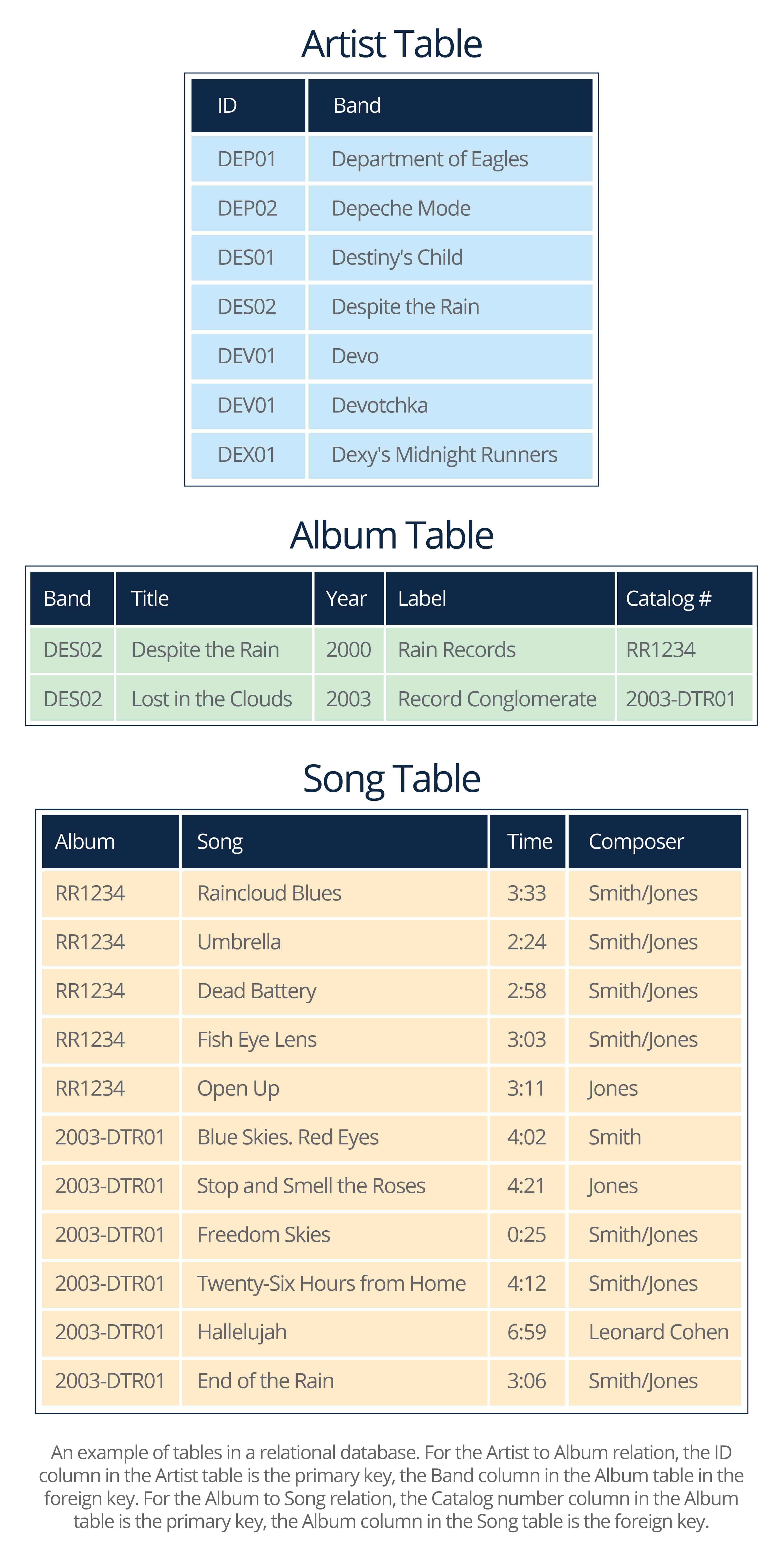
Let’s say a customer asks if you have Jeff Buckley's version of the Leonard Cohen song “Hallelujah.” With a relational database, your query may tell you that you have it on the album Grace, available as either a new CD or on used vinyl, as well as on two used CDs of Buckley’s greatest hits album. Depending on what other data you've stored, you might be able to let the customer know the price of each item, the condition of the used copies, which aisle in the store each can be found in, and that you also have versions of the song by Willie Nelson and John Cale.
Making Data Useful
In order for data to be useful, you need to know how the information is related. To create those relationships, a database administrator must become familiar with the data, as well as with the schema and business rules provided by the users. Then, they match values in tables to form relationships and create virtual records. How the tables are related will affect the design of the queries, reports, and forms that users utilize to view the data. In the above example, the database admin must understand the importance of albums, song titles, and artists for a record store owner, and then create a system that will respond to queries with clear, relevant findings.
Because data is dynamic, a database must also be able to handle the constant flux. But though data may change, relationships should be consistent. This is known as referential integrity. If a foreign key changes in a referenced table, all primary keys that reference it must be updated to reflect that. For example, if the field in the table that holds song data is changed from just the song’s title to the song’s title plus the composer's last name and the year it was written, the primary key reference in the album table must be updated or the connection between the song and the album will be broken.
What Are the Different Types of Relationships in a Database?
In databases, there are a few different terms to describe the relationships between records.
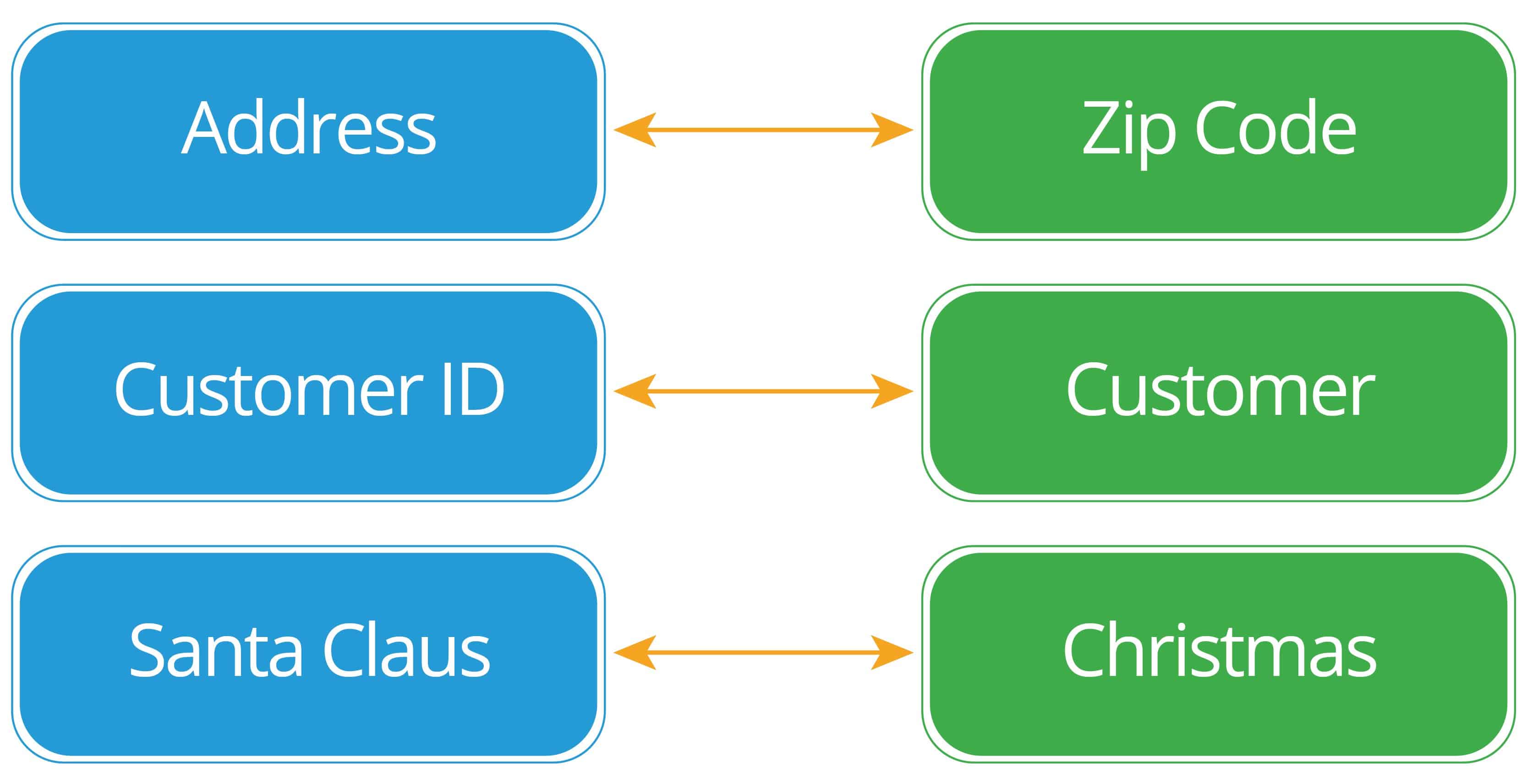
One-to-One
This the least common type of relationship, but it’s the easiest to visualize. In this relationship, there is one and only one record on each side of the relationship. Each row in a table is connected to a single row in another table. It’s pictured like this:

A one-to-one relationship is always one-to-one, no matter which table you start with.
Examples of one-to-one relationships:
- In many places in the world, a spousal relationship is one-to-one.
- Your address is related to a single ZIP code, and that ZIP code is connected to a single geographic area.
- An employee of a company has a single base-pay rate.
- Only one patron can have a copy of a library book checked out at a time.
- A customer of a business has a single customer ID.
- A student ID for a school is connected to a single student.
- Santa Claus is affiliated with a single holiday.
- A driver generally has one license.
- An edition of a book has one publisher.
- Most countries have one national flag and one capital city, though there are a few countries with two (e.g., Bolivia, Swaziland, and Honduras), and one country with three capitals (South Africa). Because of rare exceptions like this, database administrators need to carefully consider if a relationship should be set up as one-to-one.
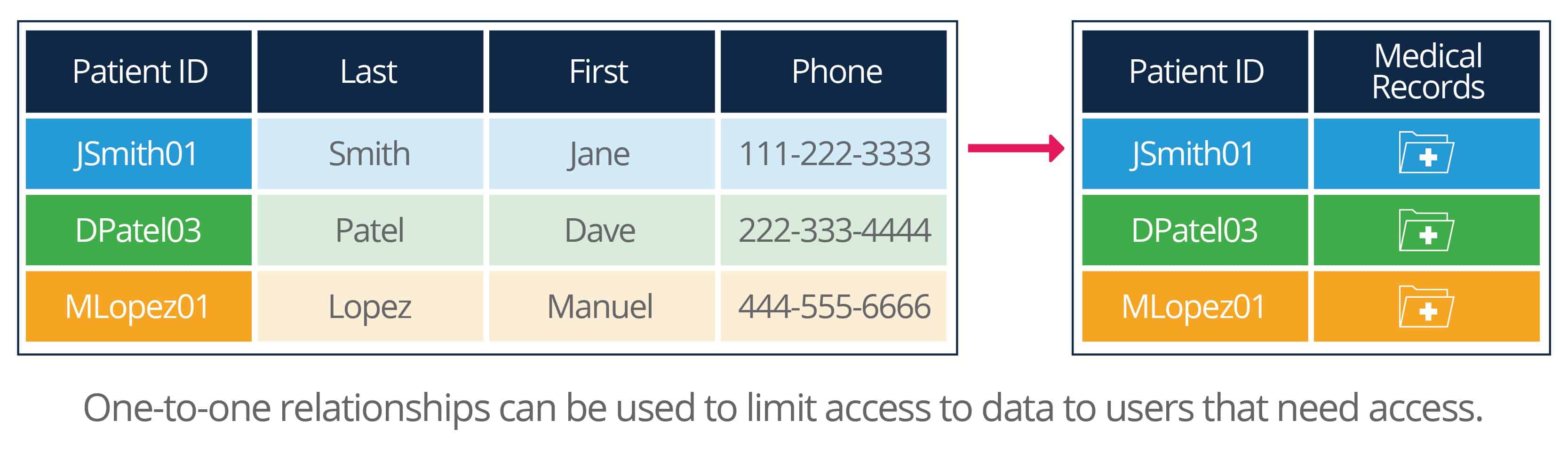
This kind of relationship doesn’t offer much in the way of data analysis (you could add more fields to the row and include all the data in one table), but it does allow different users more or less access to the data in the linked table. Let’s say a doctor’s office has a database of patients, and administrative staff should only see patient contact information, while medical staff can see that plus the medical records. By putting contact information and medical information in separate tables, database administrators could easily give the users access to only the information they should see.
One-to-Many
In this relationship, there is one record on one side of the relationship, and zero, one, or many on the other. It’s pictured like this:
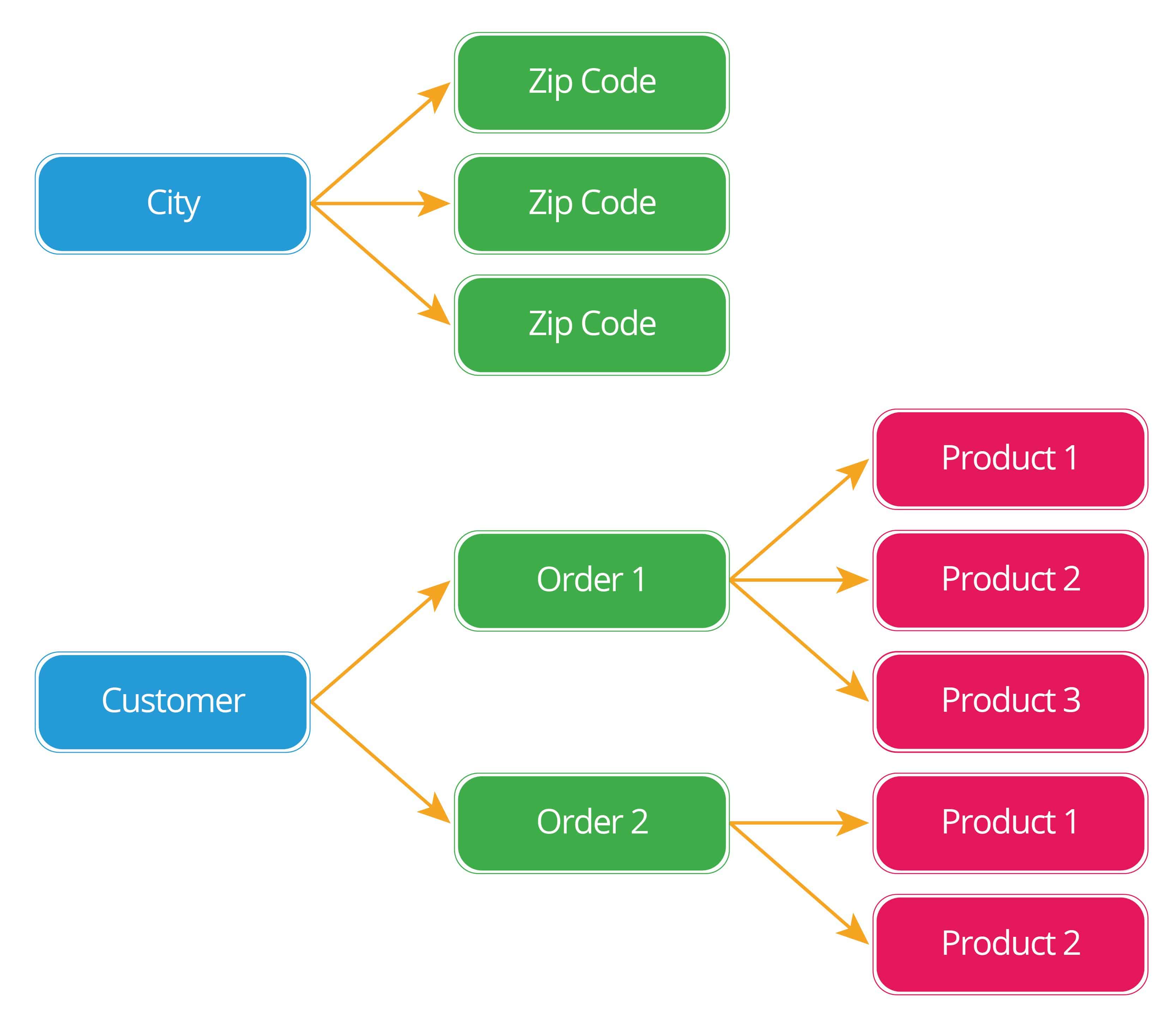
This is the most common relationship type. From the linked table, the one-to-many relationship becomes a many-to-one relationship. For example, a biological mom can have many children, but each child can only have one biological mom.
Examples of one-to-many relationships:
- One book can have more than one author. For example, the 1996 book Tube: The Invention of Television was written by David E. Fisher and Marshall Jon Fisher.
- A city can have many ZIP codes.
- A state can have multiple area codes.
- A state can have many cities.
- A customer can make many orders from a vendor, and each order can have multiple products.
- One student can be registered in many classes.
- An album (usually) contains many songs.
Many-to-Many
This is the most flexible relationship type. There is zero, one, or many records on one side of the relationship, and zero, one, or many on the other. It’s pictured like this:

Examples of many-to-many relationships:
- A book can be associated with many categories. For example, The Immortal Life of Henrietta Lacks, a 2010 book by Rebecca Skloot, is linked to the following Library of Congress categories: Lacks, Henrietta, 1920-1951--Health; Cancer--Patients--Virginia--Biography; African American women--History/Human experimentation in medicine--United States--History; HeLa cells; Cancer--Research/Cell culture; Medical ethics. Each of those categories are linked to many other books.
- The members of a family can own many pets.
- Recipes have multiple ingredients, and an ingredient can be used in many recipes.
- A doctor has many patients, and some patients see multiple doctors.
- A worker can be responsible for many tasks, and each task can be handled by many workers.
- Many customers can buy multiple products.
- Each class has multiple students; each teacher teaches multiple classes.
- A salesperson can have many clients, and each client might have many salespeople (especially if they are larger clients).
- A Twitter user probably is followed by many people and follows many others; those two groups won’t necessarily match.
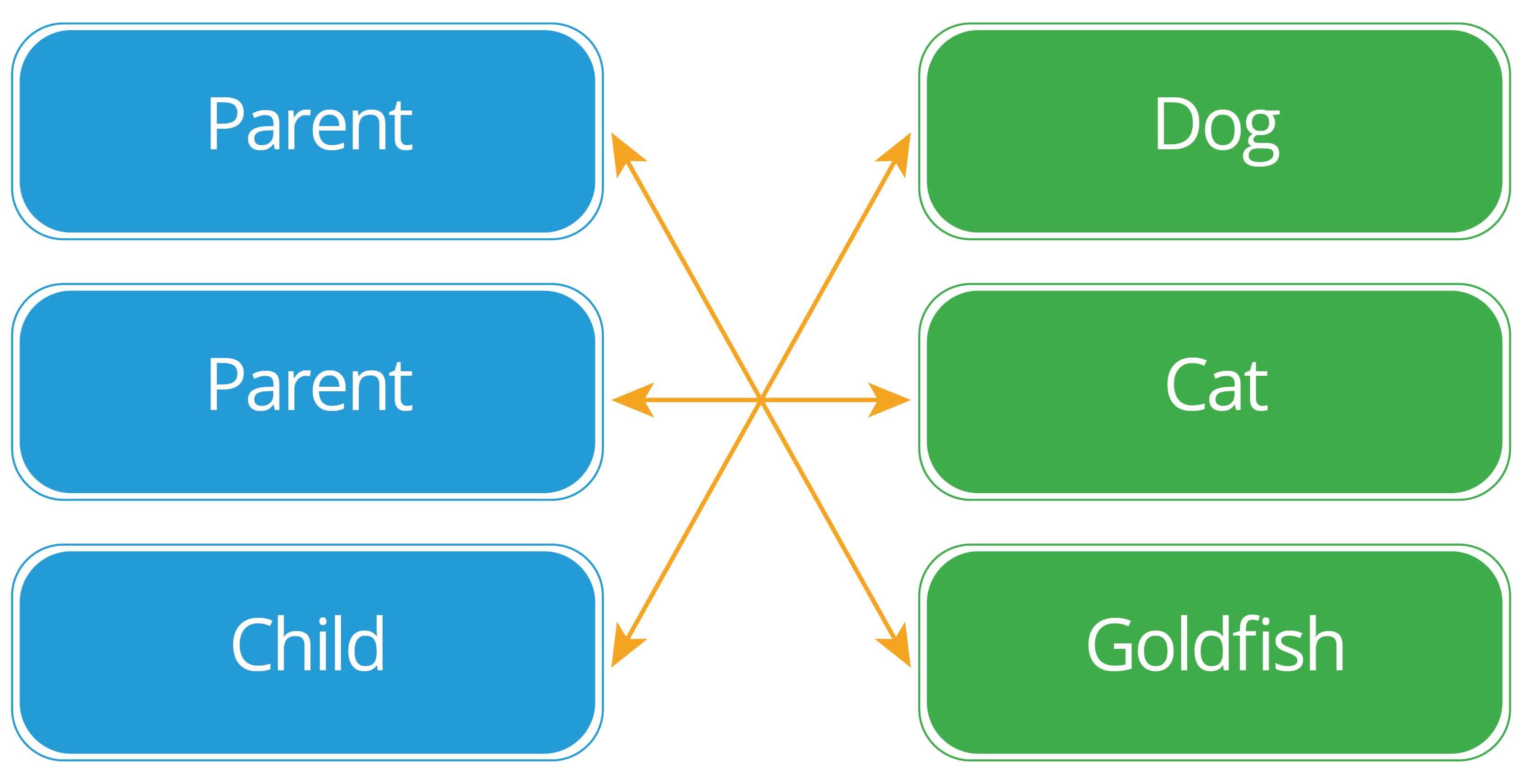
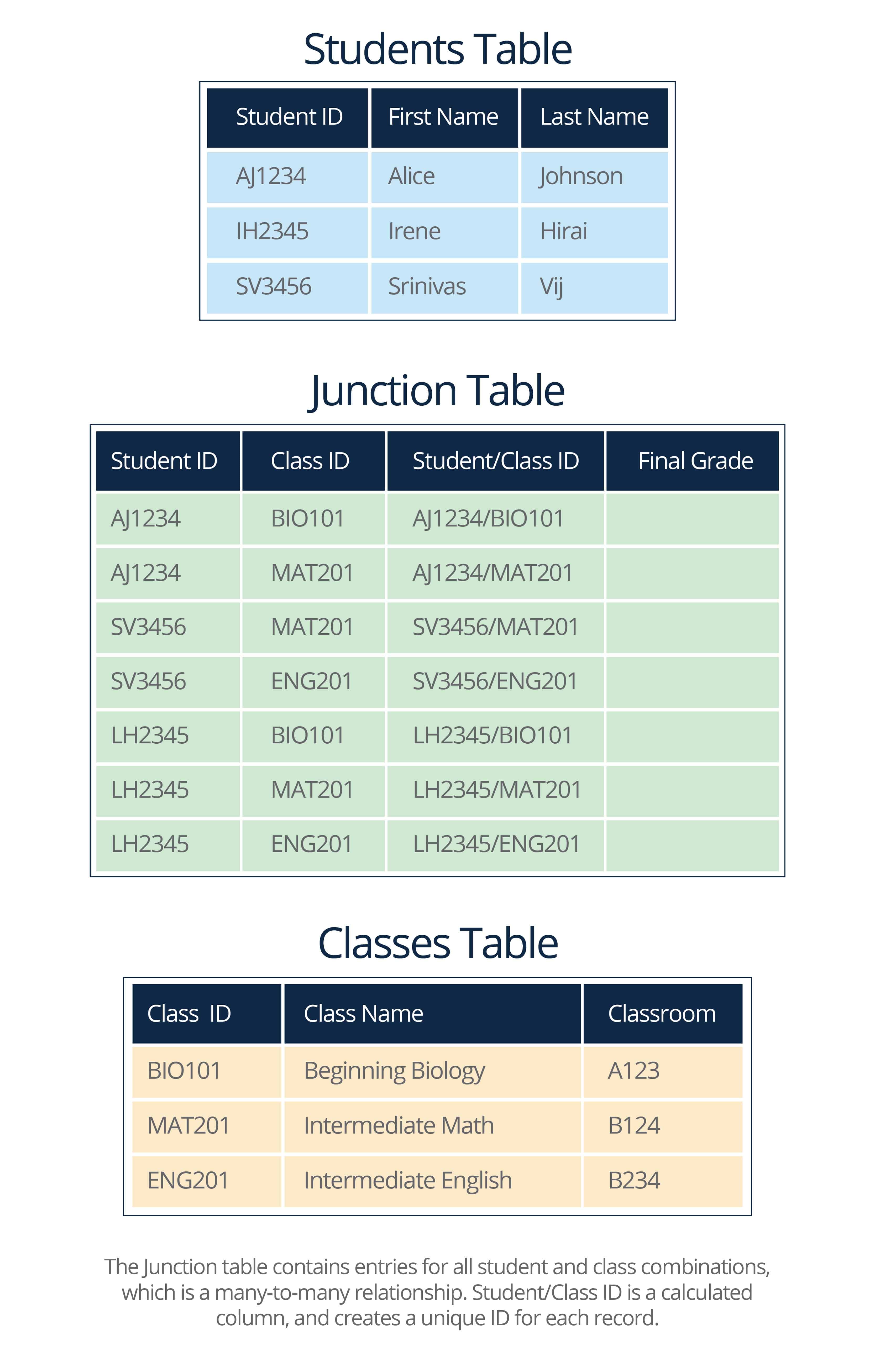
Many-to-many relationships require an intermediate table to make the connection, because relational systems can’t directly manage the connection. These tables have many names, including the following:
- Junction
- Linking
- Cross-reference
- Mapping
- Join
- Associative
A junction table works like this:
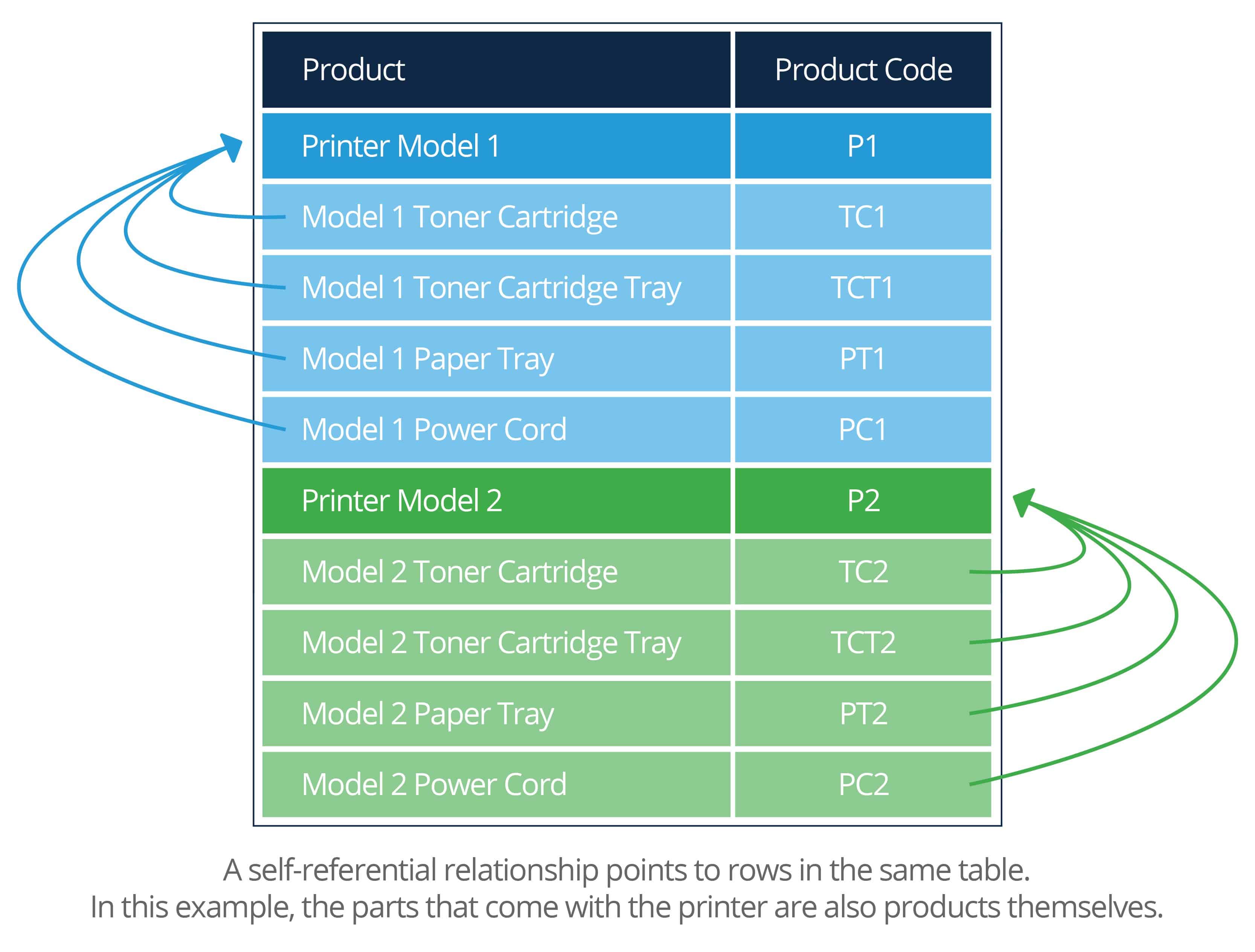
Self-Referential
A self-referential relationship is one that links to another row in the same table. This is used for specific situations — for example, if you have a list of books, and you want to connect all the volumes that come from the same series, such as Lord of the Rings or Dune. It’s diagrammed like this:
Calculated Fields
Tables can have fields that are populated with a formula instead of data. For example, in a database for an online store's orders, the total field is most likely calculated by adding the cost of all items, the taxes (which is probably a calculated field that totals the state, county, and municipal tax percentages), and shipping costs, then subtracting any discounts or promotions.
What Is a Relationship in Access?
Access is Microsoft's database program, and it uses the same concept and kinds of relationships as other databases.
What Are SQL Joins?
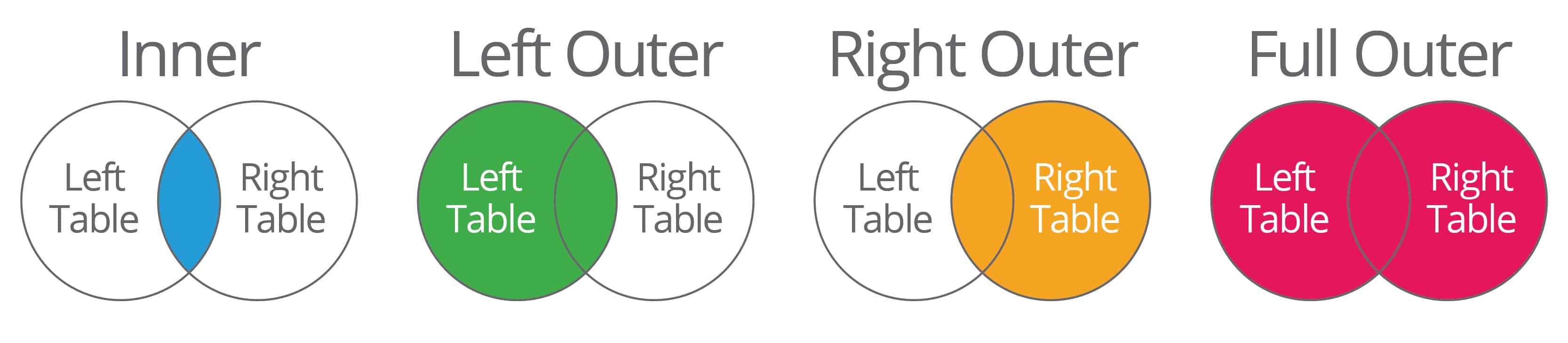
SQL (Structured Query Language) is by far the most common method used to interact with and manage databases. SQL joins are statements that allow data from two tables (which may be called parents) to be combined into a new temporary (aka child) table. (More than two tables can be referenced, but to keep the examples simple, only two will be used below.) There are a few types of joins; the most common are the following:
- Inner: Returns records in both tables where the primary key and foreign key match the query.
- Left outer: Returns all records from the left table (the one with the primary key) plus records from the right table (the one with the foreign key) that match the query.
- Right outer: Returns all records from the right table plus records from the left table that match the query.
- Full outer: Returns all records in both tables that match the query.
- Cross: Each row in the first table is joined with each row in the second. The total number of rows in the results will be the number of rows in the first table multiplied by the number of rows in the second.
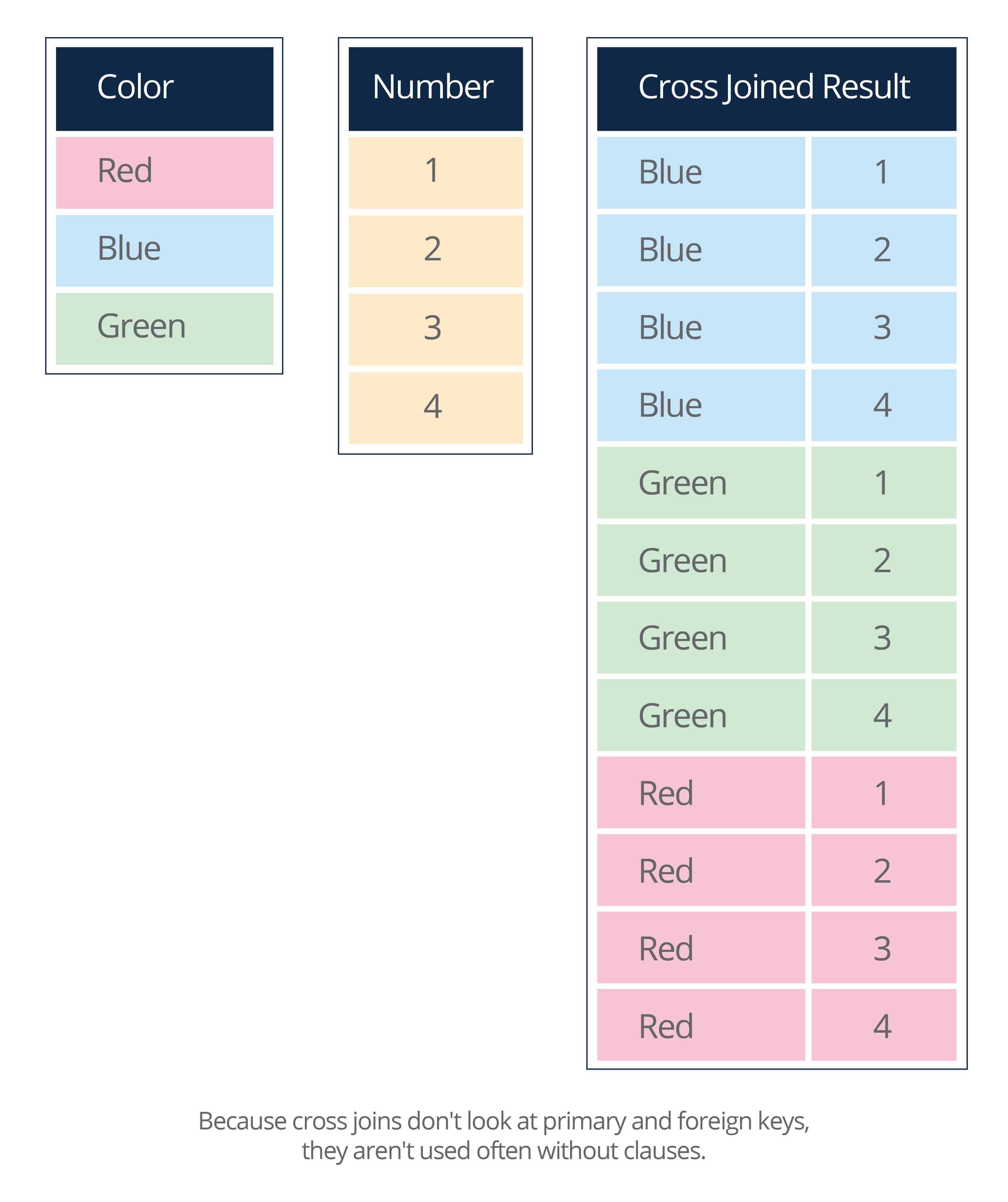
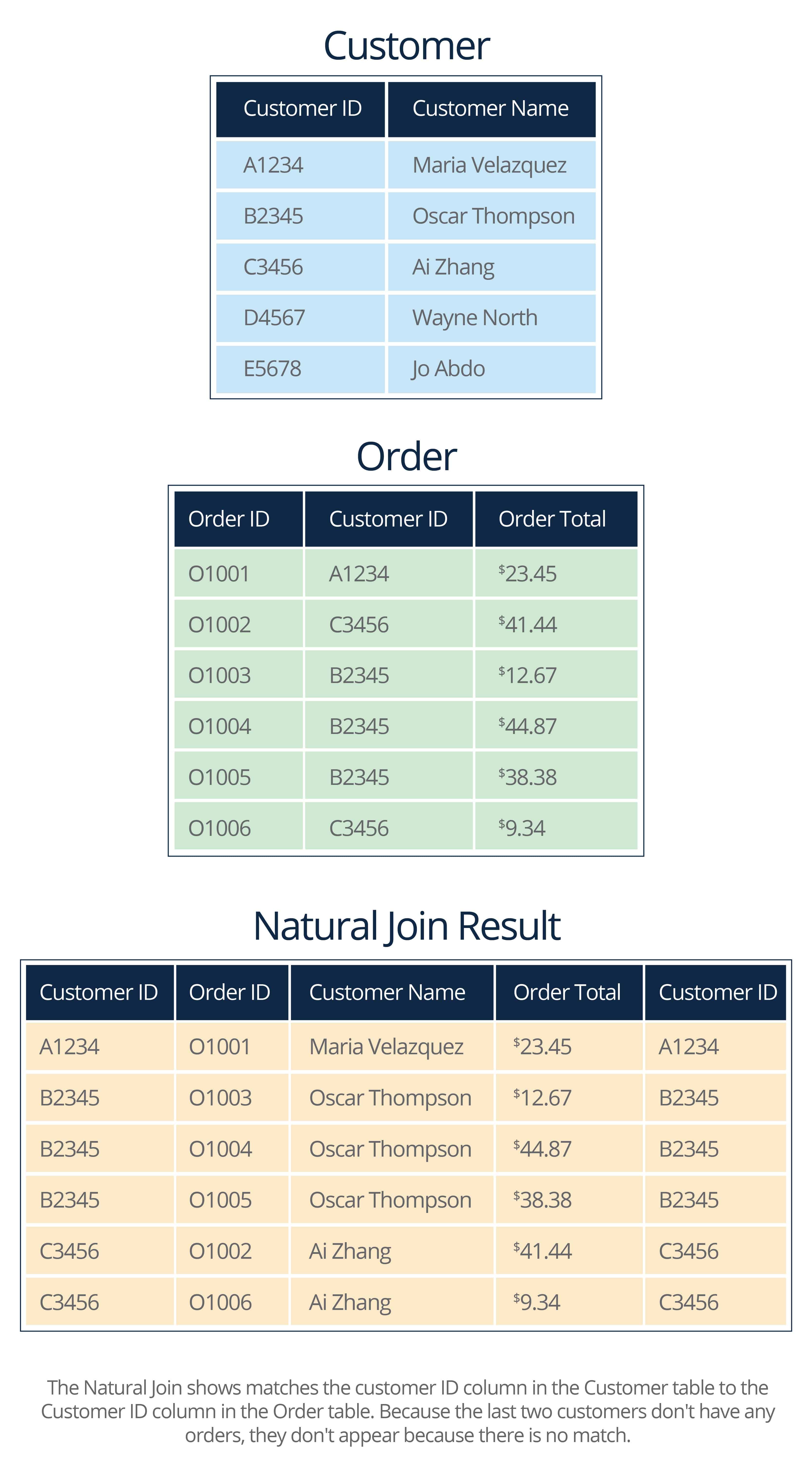
- Natural: Columns with the same name in the connected tables will appear only once.
Joins can be adjusted with clauses, such as WHERE, USING, and HAVING, which will change the data that will be returned.
More information on SQL Joins can be found at w3resource.com.
Other database languages, such as OQL and XQuery, use different terms to do the same thing.
What Is Database Normalization?
Database normalization is the foundation of relational databases. It’s the process that organizes data into tables that can then be connected to each other via the methods described above. Each table should be about a specific topic, and only those columns that support the topic are included in the table.
Database normalization provides the following benefits:
- Duplicate data is minimized, and data storage needs decrease.
- Changes to data have to occur in only one place.
- Access to the data is quicker and more efficient.
Once the data schema and business rules for the database are established, the data is processed in steps that create tables and primary keys, eliminate repetitive data, and build relationships between the data by splitting the data into new tables and creating foreign keys for those tables. The steps are called First Normal Form (1NF), Second Normal Form (2NF), and Third Normal Form (3NF). Each step attempts to further refine the data and narrow the focus of each table.
Complicated data schemas may require fourth and fifth normal forms. There are variations of forms, such as the Boyce–Codd Normal Form (BCNF), which is a more robust version of the 3NF, and is used in unique situations.
A full description of the normalization process is beyond the scope of this article, but an excerpt from the 2002 book Absolute Beginner's Guide to Databases by John Petersen, available on the informIT website, covers it well.
Improve Database Relationships with Smartsheet for IT & Ops
Empower your people to go above and beyond with a flexible platform designed to match the needs of your team — and adapt as those needs change.
The Smartsheet platform makes it easy to plan, capture, manage, and report on work from anywhere, helping your team be more effective and get more done. Report on key metrics and get real-time visibility into work as it happens with roll-up reports, dashboards, and automated workflows built to keep your team connected and informed.
When teams have clarity into the work getting done, there’s no telling how much more they can accomplish in the same amount of time. Try Smartsheet for free, today.